Unveiling AI Expertise in Finance: A Comparative Analysis of Open-Source LLMs
Access Our GitHub Repository: Visit our GitHub page to explore the datasets, download the code, and view the documentation related to our testing of open-source Large Language Models. This repository is intended to serve as a resource for educators, researchers, and anyone interested in AI model testing.
Introduction:
In the rapidly evolving world of finance, the integration of artificial intelligence has become a cornerstone for driving innovative solutions and enhancing decision-making processes. Recently, I embarked on a fascinating journey to evaluate the capabilities of various open-source Large Language Models (LLMs) specifically tailored for financial question and answer scenarios. My goal was to understand how these models perform under a standardized prompt setup, where each model acted as a ‘financial analyst’ to answer queries succinctly in JSON format. This analysis not only sheds light on the current state of AI in financial inquiries but also aims to guide future developments and implementations in financial tech landscapes
Objective of the Test
The primary objective of this exploratory analysis was to determine which open-source Large Language Model (LLM) is most adept at handling specific tasks within the financial sector. This initial test focused on two key areas:
- Financial Terminology Understanding: The ability of each model to accurately comprehend and respond to queries involving complex financial terminology. This is crucial for ensuring that AI applications in finance are reliable and informative.
- Basic Financial Reasoning: Assessing each model’s capability to perform basic reasoning about trading and investment scenarios. This includes understanding market dynamics, predicting potential financial outcomes, and offering preliminary financial advice based on given data.
The aim was to identify which LLM offers the most effective and accurate performance for these tasks, providing valuable insights for future AI implementations in financial services. By conducting this analysis, we can better understand the strengths and limitations of each model, guiding developers and businesses in choosing the right AI tools for their specific needs in the finance domain.
Methodology
To carry out this comprehensive evaluation of open-source Large Language Models (LLMs) for financial Q&A tasks, I employed a structured and replicable testing approach using the following methodology:
Tool Used:
- ollama: All tests were conducted using ollama, which allows for consistent and fair comparisons across different LLMs. This tool provided a standardized environment to run each model under the same conditions.
Dataset Creation:
- Question Generation: The dataset for this test was uniquely generated using ChatGPT-4, ensuring that each question was relevant to financial terms and basic trading concepts. This approach helped in maintaining the quality and specificity of the dataset, focusing on the financial domain. The Basic Financial Trading Q&A v0.3 dataset can be download from GitHub.
- Verification of Answers: Each question was designed to have a simple, verifiable answer to facilitate straightforward evaluation of the model outputs. This ensures that the accuracy of each model could be objectively assessed.
Test Execution:
- Repeated Trials: Each question was processed several times by each model to account for variability in responses. This repetition helped in assessing the consistency of each model in providing correct and reliable answers.
- Uniformity in Queries: To ensure that all models were evaluated under identical conditions, the same prompt template was used across all tests. Models were instructed to act as a financial analyst and respond only in a predefined JSON format, focusing strictly on the answer without additional explanations.
This methodology not only provided a robust framework for evaluating the capabilities of each LLM but also ensured that the findings were grounded in a consistent and transparent testing process.
Physical Environment
To facilitate an efficient and effective testing environment for evaluating the performance of open-source Large Language Models on financial Q&A tasks, we developed a cutting-edge multi-agent system. This setup utilized the advanced capabilities of multiple Mac computers, specifically leveraging their high-performance features. Here’s an overview of the setup:
Hardware Utilized:
- Mac Studio with M2 Ultra Chip: The backbone of our testing environment comprised several Mac Studio units equipped with the M2 Ultra chip, featuring 192GB of unified memory. This powerful configuration is particularly suited for running large-scale models, such as the 132-billion parameter model we tested, ensuring smooth operation and rapid processing times without compromising on computational efficiency.
- Mac Mini with M2 & M3 Chips: Smaller Macs with up to 64GB unify memory to do jobs for smaller models.
System Configuration:
- Multi-Agent System: We engineered a multi-agent system to manage and distribute tasks across multiple Mac computers seamlessly. This system was crucial in handling the computational load and coordinating the workflow, thereby maximizing the use of hardware resources. The multi-agent approach allowed for parallel processing of tasks, significantly speeding up the testing process and enhancing productivity. This MAS setup also ensure every computers run suitable jobs. The 192GB Mac Studio take workload for larger models first.
- Automated Task Handling: Automation was a key component of our system. Each task, from initiating model runs to collecting outputs, was automated. This not only reduced the potential for human error but also ensured that each model was tested under precisely the same conditions, thus maintaining the integrity and consistency of our tests.
This robust physical setup enabled us to conduct extensive testing without the typical constraints associated with processing large datasets and complex models. By leveraging advanced hardware and custom software solutions, we ensured that our evaluation of LLMs was not only thorough but also efficient and scalable.
Results
This is a summary for correct and incorrect answers by models. The full result can be download from our GitHub testset_20240525–1_results.csv.
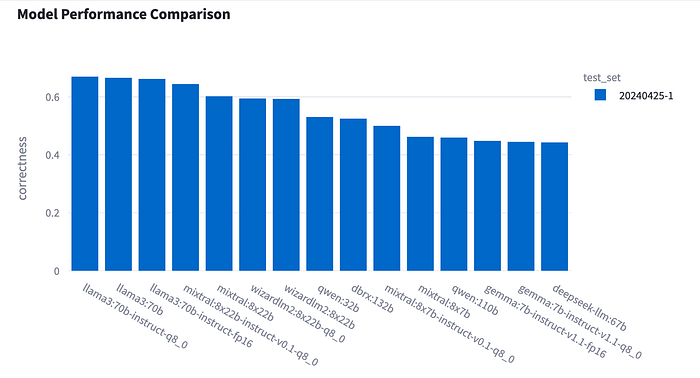
Analysis
- Llama3:70b Family: The models in the ‘llama3:70b’ family demonstrated the strongest performance in the financial Q&A tests. This suggests that their training and architecture are particularly well-suited for handling the nuances of financial terminology and reasoning tasks. Their high accuracy rates indicate robust language understanding capabilities, crucial for precise financial analysis.
- Mixtral:7x22b and Wizrdlm2:8x22b: These models also performed commendably, ranking just behind the ‘llama3:70b’ family. The slightly lower performance compared to the ‘llama3:70b’ models could be attributed to variations in their training datasets or model architectures, which might affect their efficiency in specific financial queries.
- Larger Models Underperforming: Surprisingly, larger models like ‘dbrx:132b’, ‘command-r-plus:104b’, and ‘qwen:110b’ did not meet expectations despite their extensive number of parameters. This underperformance could be due to overfitting, where the models are too tailored to their training data, reducing their practical effectiveness in real-world tasks like the financial Q&A scenarios tested.
- Gemma:7b-v1.1’s Surprising Success: The ‘gemma:7b-v1.1’ model, despite being smaller in scale, achieved a correctness rate of about 45%. This unexpected success highlights that efficient training and model optimization can sometimes outweigh the sheer scale of parameters in language models. It suggests that ‘gemma:7b-v1.1’ may have specific strengths in processing and understanding financial content, potentially through more focused training on relevant datasets.
Impact of Quantization on Model Performance
Our findings suggest that the level of quantization — essentially, the detail and precision within a model’s numerical calculations — may not uniformly influence the correctness of model responses across different architectures. This insight emerges from observing the performance differences among various models with differing quantization levels:
- Consistency in Llama3 Precision: The three different precision variants of the ‘llama3’ model displayed nearly identical levels of correctness. This consistency indicates that for the ‘llama3’ architecture, modifications in quantization did not significantly impact the model’s ability to correctly answer financial Q&A tasks. It suggests that the ‘llama3’ model’s architecture is robust enough to maintain performance despite changes in computational precision.
- Variability in Mixtral Performance: In contrast, the ‘mixtral:8x22b’ model showed a notable difference in performance between its quantization variants. Specifically, the q8_0 version demonstrated significantly higher correctness compared to the q4 version. This variation highlights that for some models, like ‘mixtral’, lower quantization (such as q4) might degrade performance, possibly due to the reduced ability to handle nuances in language processing or losing critical information during model computation.
These observations underline the importance of considering model-specific characteristics when adjusting quantization levels. While some models may not exhibit substantial performance degradation with lower precision, others might require higher quantization to function optimally, especially in tasks demanding high accuracy and nuanced understanding, such as in financial analytics.
By further exploring these differences, we can better tailor model configurations to specific applications, optimizing both computational efficiency and task effectiveness.
Conclusions
The results of this testing exercise offer valuable insights into the performance of various Large Language Models (LLMs) in handling financial Q&A tasks, but they also warrant careful interpretation:
- Task-Specific Performance: The higher correctness rates observed in models like the ‘llama3:70b’ family suggest that these models are particularly adept at handling the specific financial Q&A tasks they were tested on. However, this does not necessarily imply that these models are superior in all aspects of language processing or other types of tasks.
- Variability in Model Performance: It’s important to note that some models may excel in specific types of questions within the same test set. This variability indicates that while some models are tuned to perform well broadly, others may have specialized capabilities that make them more suitable for particular sub-tasks or question types.
- Influence of Prompt Template: The correctness of the responses is also significantly influenced by the prompt template used in the tests. Different formulations of prompts can lead to variations in how models interpret and respond to questions, affecting their apparent performance. This factor must be considered when evaluating model capabilities and when designing tasks for these models in practical applications.
- Broader Implications: These findings emphasize the importance of context and specificity in deploying LLMs in real-world scenarios. Users and developers should consider the particular strengths and limitations of each model, especially in specialized fields like finance, to ensure optimal performance and reliability.
This analysis not only helps in understanding the current capabilities of state-of-the-art language models in financial contexts but also underscores the nuanced nature of AI performance, which can vary significantly depending on the task and conditions.
Future Work
Building on the insights gained from this initial testing phase, our future work will aim to expand and deepen our understanding of the capabilities of open-source Large Language Models (LLMs) across various domains. Here’s what we plan to explore next:
- Diverse Prompt Templates: Recognizing the impact of prompt design on model performance, we will experiment with a variety of prompt templates. This approach will help us assess how different prompt structures influence the accuracy and relevance of model responses, enabling us to fine-tune these inputs for optimal outcomes.
- Expansion of Q&A Sets: We will develop additional Q&A sets specifically tailored to the financial sector and beyond. By broadening the scope of our queries, we aim to create a more comprehensive dataset that tests a wider range of financial knowledge and analytical skills.
- Exploration Beyond Finance: While our current focus has been predominantly on financial topics, we plan to extend our testing to other areas. This expansion will include sectors such as healthcare, legal, and technology, where the precision and adaptability of LLMs can significantly impact decision-making processes and operational efficiency.
- Comparative Performance Analysis: As we expand our testing into other domains, we will also conduct comparative analyses to identify which models perform best in specific contexts. This will provide valuable insights for developers and businesses looking to implement AI solutions tailored to their specific needs.
Through these initiatives, we hope to not only enhance the utility of LLMs in practical applications but also contribute to the broader AI community by sharing our findings and methodologies. Our goal is to pave the way for more informed and effective use of AI technologies across various industries.
Get Involved
We are committed to expanding our testing of open-source Large Language Models (LLMs) and would love to include contributions from our readers. Your input can help enhance the accuracy and relevance of our future tests.
We invite you to participate in the following ways:
- Submit Your Q&A: If you have questions or answers that you believe would challenge or provide new insights for these LLMs, please share them with us. Whether they are finance-related or pertain to other sectors, your contributions are valuable.
- Propose Prompt Templates: The structure of prompts plays a crucial role in how models interpret and respond to queries. If you have ideas for prompt templates that could potentially yield more nuanced or detailed responses from the models, we would be eager to test these in our upcoming experiments.
How to Contribute: Please send your Q&A suggestions and prompt templates to support@osmb.ai. We will review all submissions and consider including them in our future tests. This is a great opportunity to see how cutting-edge AI models handle real-world queries and to contribute to the advancement of AI research.
By participating, you will be contributing directly to the field of AI and helping shape the future of technology in various industries. We look forward to your insights and thank you in advance for your valuable contributions!